Demystifying and Debunking ML Part 1: Foundations of Machine Learning in ChemEng
Hugh Stitt, Joe Emerson, Carl Jackson and Robert Gallen introduce the first in a four-part series exploring how chemical engineers can critically assess, apply and benefit from machine learning
Quick read
- ML is not new — but newly powerful: Machine learning builds on long-standing statistical and mathematical principles, but advances in computing power and data handling have dramatically expanded its usefulness in chemical engineering
- Data quality is everything: The success of an ML model depends far more on careful data preparation — cleaning, scaling, feature selection and validation — than on algorithmic complexity
- Critical thinking beats hype: ML can deliver real value where data are rich but theory is sparse, yet it demands rigorous scrutiny. Understanding how models are built and validated is essential to separating sound engineering insight from overfitted illusion
MACHINE LEARNING (ML) modelling has been around in chemical engineering for over 50 years but has seen an explosive increase in the last 10–20 years. Most chemical engineers are, however, not well schooled or trained in this branch of mathematics. How then can one identify if it is a good approach for a specific problem or, indeed, assess the quality of the modelling in a paper or report? We were all taught at university about modelling using, say, differential equations. Not so with ML. In this series of four articles, we will attempt to demystify and debunk ML, hopefully enabling readers to better understand when to exploit ML and how to assess work based on ML.
Series scope and objectives
The four articles in this series will address the key elements of ML applied to chemical engineering. This is not a guide to doing ML. There are many texts and courses that expertly fulfil that purpose. Rather, our intent is to enable the non-expert or non-practitioner to interrogate ML projects and reports by awareness of the key elements that underpin good ML practice.
This first article will introduce some the fundamentals of ML mathematics, the structure of a typical ML project, present some examples of ML applied to chemical engineering and some salutary tales.
The second will address the data. In data driven modelling the quality of the input data is self-evidently critical.
How should data adequacy be assessed and the data be prepared? How should key features be extracted?
The third will consider predictive model selection, optimisation and testing. These are the critical steps where conscious or subconscious “cutting corners” is fatal to model performance.
The final article will present some advanced options such as Explainable AI (XAI) and Hybrid (theoretical – ML) modelling that we believe are key future areas for engineers. We will conclude the series by introducing the concept of “Machine Learning Crimes”.
Historical context
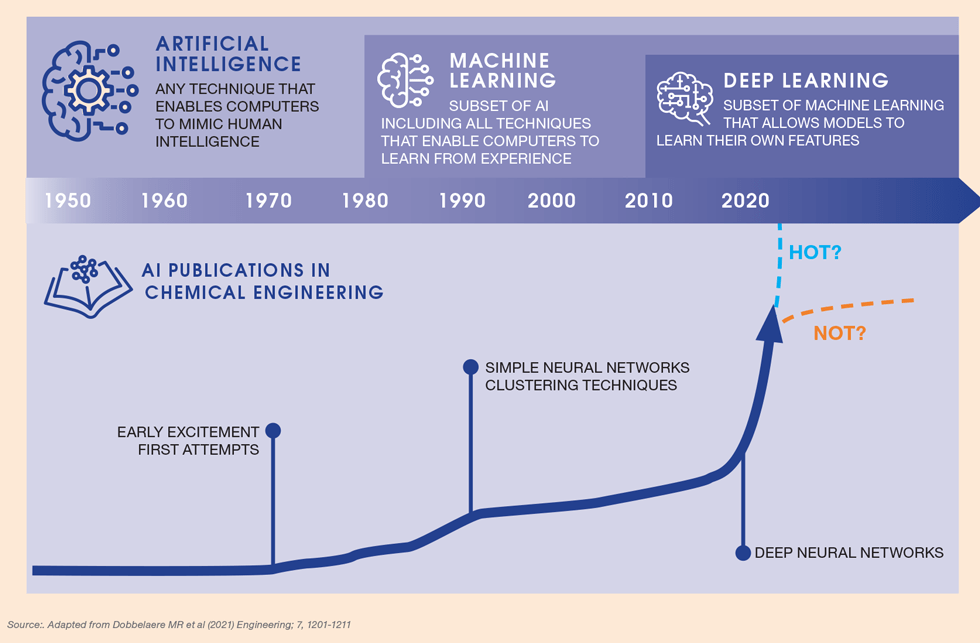
ML is essentially a branch of statistics, and its application in engineering commonly a variant on (non-linear) regression. As a mathematical discipline it is not new. Even its use in chemical engineering is not new (see Figure 1). Pioneering examples included process synthesis and process fault detection. Improvements in computing power, data handling and programming have driven the rise in popularity. Despite the hype, it does not bring in new laws of mathematics. Almost ten years ago, we published an article in TCE1 querying the validity of our models, highlighting aspects of model structure, fitting or parameterisation and validation.
With ML-based modelling, all of this remains true. A mathematically ill-conditioned optimisation remains ill-conditioned – but now called “over-fitted”. The statement that “fitting a model against one objective function (eg R2) can lead to a poor model”1 remains true. In reality, ML models require even greater scrutiny to structure, fitting and validation than theoretically based models.
Epithets such as “AI lies at the heart of failure” reveal a healthy degree of scepticism. We are, though, here to praise Caesar, not to bury him. ML is a very powerful tool, notably where we are data rich but sparse in fundamental equations. But when should we use it, and how can we ascertain whether to believe it?
Machine learning basics
ML is not just glorified statistics; rather statistics is a critical component. In this section we will try to briefly explain the basics of ML.
ML Modelling Project Structure

The typical workflow of a ML project (see Figure 2) emphasises that the vast majority of the effort lies in the data generation pre-processing and preparation. The ML modelling part is, cynically, just glorified (albeit skilled and painstaking) model fitting.
The importance of these inglorious early stages of “data wrangling” to the resulting model cannot be overemphasised. George Fuecshel’s phrase “GIGO” (Garbage In, Garbage Out), coined at IBM nearly 80 years ago, is still just as true today. A good ML study report should include how the data were collected, collated, cleaned, transformed and scaled, as well as discussion of the detection and removal of outliers and bias. The methods used for feature reduction and selection should also be explained, as well as the approach to splitting data into training, testing and validation sets. If your source does not disclose the approach and methods of data pre-processing then, as a rule, ask or be circumspect.
ML algorithms

There is a huge number of ML algorithms. How should a study go about selecting the best options? As engineers, we will generally be dealing with “tabulated” data, primarily numerical variables, plus maybe some “categorical” (non-numerical) variables. The objective is likely to be establishing key inter-relationships or achieving a regression model.
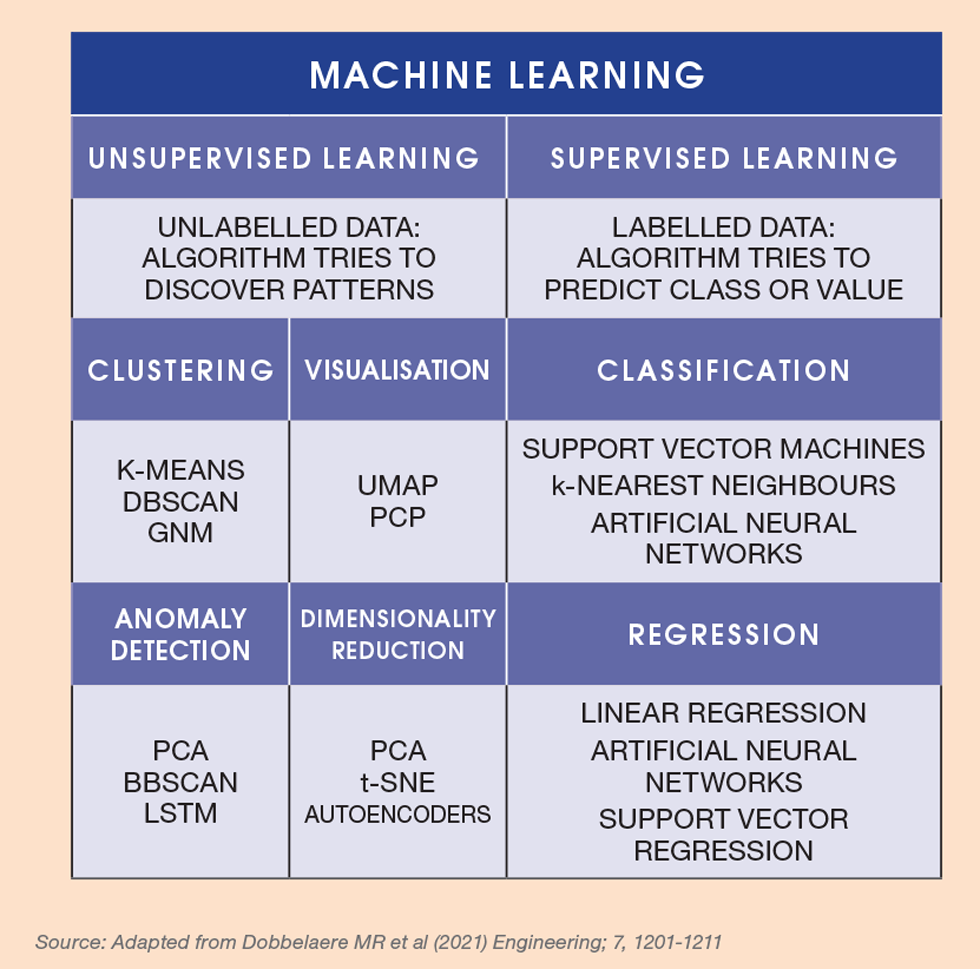
The jargon and variety of ML algorithms can be bewildering to the newcomer. Here is a short breakdown of algorithm classes and how they work (see Figure 3):
- Unsupervised learning: unlabelled data are used to reveal patterns and data groupings. Applications include fault detection and diagnosis
- Supervised learning: labelled data are used to establish predictions of values by regression or classification; what we all think of as modelling
- Reinforcement learning: learns from “rewards” and “penalties” through interaction with the “environment” to optimise success. This approach underpins autonomous systems such as driverless cars and robots and some applications in process control
There are a number of generic classes of ML algorithm spread across these basic approaches. The names are reasonably descriptive:
- Latent variables: reducing the dimensionality of the data. The most common example is principal components analysis (PCA). Regression models can be built using latent variables
- Clustering: grouping sets of similar data based on defined criteria. It is useful for segmenting data and performing analysis on each group to find patterns. An example is k-means clustering
- Classification: splitting the data into classes, generally based on the output variable(s): flow regimes for example. Classification can involve two or more dimensions. K-Nearest Neighbours and Support Vector Machine are examples
- Regression: predicting an output variable based on the input data: probably the leading use of ML in engineering. Common examples include Partial Least Squares, Gaussian Process Regression and various neural networks
The use of optimisation, convergence and search methods is common in building and deploying ML. These include Evolutionary Algorithms (such as Genetic Algorithms) and Bayesian approaches. However, these are tools and are not normally classified as ML in the strictest sense.
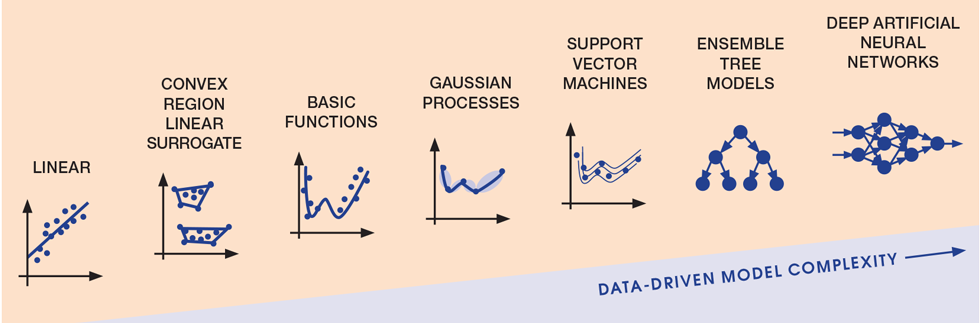
Model complexity is an important consideration. Figure 4 provides a summary of models of increasing complexity in the context of optimisation, emphasising the breadth of approaches, complexity and options.
Not all algorithms give information or statistical outputs that allow interrogation of the model. Some give information on input variable importance (or loadings), such as Partial Least Squares (PLS). Others, including most embodiments of Neural Networks, give little or no information other than confidence intervals of the predicted variables. This option for “explainability”, which will be covered in the fourth article, can have a major impact on algorithm selection.
Building an ML model
Algorithm selection is largely driven by the nature of the data and the problem: a classification problem needs a classification algorithm etc. For a regression problem, after preliminary data cleaning, exploration and analysis are complete, apply Occam’s Razor: use the simplest feasible algorithm.
An ML study should tell you why they have used the selected algorithm. Various algorithms will hopefully be trained, and each subject to some optimisation (hyperparameter tuning) – not just tested at the “default structure”. The models should then be validated and tested on unseen data: data not used in the training (or fitting to use a more familiar term). Quoted model performance must be based on the validation or preferably test scores: never the training score.
And then, eventually, you hopefully have a model that can be used to predict new data within the domain of the input data. ML models are purely empirical and, as we all learned as undergraduates, are thus valid only in the range of the data used to derive them.
Unlocking potential: what machine learning can do for you
Catalyst deactivation
Deactivation modelling is problematic as it depends on the deactivation mechanism and the process history, such as flow rate, conversion and temperature. In this study,2 an industrial ethylene oxide reactor is modelled using traditional first-principles kinetic and reactor equations, supplemented by a Support Vector Regression (SVR) deactivation model. The SVR is built using a limited set of input parameters, selected using domain expertise. The resulting model achieves prediction errors of less than 5% and its use in the operational control of an industrial unit is demonstrated.
Powder flowability
A Random Forest model can reliably classify the shear cell Flow Function of unseen powders (eg, easy flowing, cohesive).3 The input data comprised 112 powders including particle size (d10 d50, d90), bulk density, surface energies and shape factors.
Flow regime classification
The gas-liquid mixing regime (flooding, loading, dispersed) of a sparged stirred tank is predicted using acoustic emissions.4 PCA is applied to reduce the dimensionality of the frequency-domain acoustic data, retaining only three principal components. A Support Vector Machine model, incorporating these components along with impeller speed and sparge rate (VVM) can predict the flow regime with high accuracy.
Plant fault detection & diagnosis (FDD)
The detection from plant data of either a sensor error or a genuine plant fault was an early application of ML in chemical engineering. The use of Neural Networks was proposed over 35 years ago. Condition monitoring for individual equipment items such as compressor or pump drives is essentially a subset of overall plant monitoring. It is generally recognised that no single ML method will detect all faults, and as such there are proposals and implementation of many different algorithms and approaches.5 This application represents a huge success for ML.
Control and systems engineering
This and FDD are the biggest application of ML in the process industries. This is essentially displacing traditional models for Model-Based Process Control with a data-driven model: the so-called “digital twin”. Artificial Neural Networks coupled with genetic algorithms were implemented on petrochemical plants back in the 1990s. A huge range of approaches and methods are now used in practice.6 So-called soft sensors are where you find the data can be used to infer a (relative) measurement you would really like to make. For example, from pump speed, torque (or current) and delivered flow you can derive a relative value for viscosity. Industrial use seems to favour classical ML methods such as PLS and SVM.7
Process and equipment development
Automated self-optimisation of multi-step processes – often involving multiple objectives – is an intriguing application of machine learning. Surrogate ML algorithms are applied to the optimisation of a typical pharmaceutical production line, encompassing both synthesis and product work-up stages. This approach significantly accelerates process development.8
Getting it wrong - infamous ML bloopers
There are countless amusing stories of people posing absurd questions to Large Language Models (LLMs) and receiving equally silly answers. However, a growing number of serious cautionary tales are emerging – stories with significant implications for both business and science:
- Zillow Offers: an online real estate firm adopted an ML-based algorithm for predicting house prices. The company subsequently incurred losses estimated at US$304m due to the inaccuracy of future price predictions9
- Covid diagnosis: during the pandemic, many groups applied ML to help hospitals more rapidly triage patients. None of the models were apparently fit for clinical use due to flaws in the ML methodology and underlying bias in the input data10
- Facial recognition: a study by the ACLU (American Civil Liberties Union) using Amazon’s Rekognition software infamously falsely matched 28 members of US congress with police mugshots of criminals.11 While there is debate, there were clearly issues with the algorithm and its training
A growing number of serious cautionary tales are emerging – stories with significant implications for both business and science
To avoid sparking controversy we will be deliberately light on chemical engineering examples. Here though is one true story, albeit anonymised.
A data science company, tasked to analyse five years of data from a catalytic hydrotreating reactor concluded that there was no relationship between operating temperature and reaction conversion. How so, given our belief in the Arrhenius equation? The data analysis overlooked the time-series nature of the data, specifically that operating temperature is increased over time to maintain conversion, compensating for catalyst deactivation.
Having introduced the fundamentals of machine learning, in the next article we will explore the data that drive ML.
Hugh Stitt is a senior research fellow at Johnson Matthey, where Robert Gallen is a principal engineer and Joe Emerson and Carl Jackson are senior digital chemical engineers
References
- www.thechemicalengineer.com/features/models-of-good-behaviour/
- N Luo, W Du, Z Ye, F Qian (2012) Development of a Hybrid Model for Industrial Ethylene Oxide Reactor: Industrial & Engineering Chemistry Research: https://doi.org/10.1021/ie202619d
- Machine learning approaches to the prediction of powder flow behaviour of pharmaceutical materials from physical properties: https://rsc.li/46QlMh1
- Use of acoustic emission in combination with machine learning: monitoring of gas–liquid mixing in stirred tanks: https://doi.org/10.1007/s10845-020-01611-z
- Fault Diagnosis of the Dynamic Chemical Process Based on the Optimized CNN-LSTM Network: https://pubs.acs.org/doi/10.1021/acsomega.2c04017
- Industrial data science – a review of machine learning applications for chemical and process industries: https://doi.org/10.1039/D1RE00541C
- Machine learning for industrial sensing and control: A survey and practical perspective: https://doi.org/10.1016/j.conengprac.2024.105841
- Automated self-optimisation of multi-step reaction and separation processes using machine learning: https://doi.org/10.1016/j.cej.2019.123340
- Zillow’s artificial intelligence failure and its impact on perceived trust in information systems: https://doi.org/10.1177/20438869241279865
- Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans: https://doi.org/10.1038/s42256-021-00307-0
- Amazon’s Face Recognition Falsely Matched 28 Members of Congress With Mugshots: https://bit.ly/aclu-org-face-recognition
Recent Editions
Catch up on the latest news, views and jobs from The Chemical Engineer. Below are the four latest issues. View a wider selection of the archive from within the Magazine section of this site.



